
Outros
DBSCAN: a metodologia para o entendimento de comportamento baseado em geolocalização

Quando falamos em dados de geolocalização, muita gente imagina apenas um “pontinho no mapa”. Mas, na prática, o valor real desses dados está no padrão, não no ponto isolado.
Um único sinal de localização diz pouco. Agora, centenas ou milhares de sinais ao longo do tempo contam histórias.
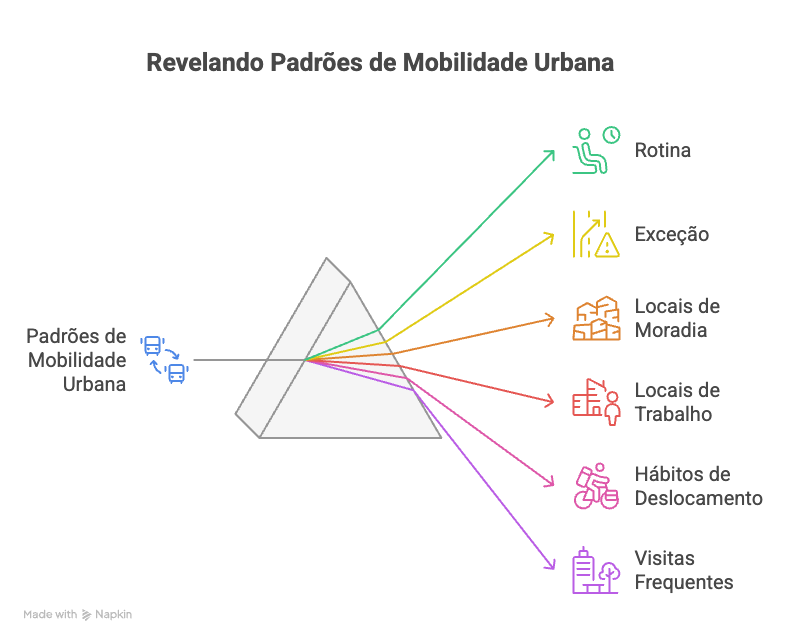
É a partir dessa repetição de horários, lugares e frequência que conseguimos inferir comportamentos, que aqui na Hands apelidamos de GeoBehavior lá em 2018. Através dele que desta análise que conseguimos inferir:
- Região provável de moradia
- Região provável de trabalha
- Lugares visitados com frequência
- Deslocamentos recorrentes que definem uma rotina
- Ou mesmo pontos ocasionais, mas que são relevantes por grande concentração de pessoas: shows, eventos esportivos, festas etc
Mas como organizar bilhões de dados de milhões de pessoas que podem estar em dezenas de milhões de locais? Simples, através de metodologias de estatística e probabilística, sem depender de dados declarados.
O desafio: transformar pontos soltos em comportamento
Os dados de geolocalização brutos costumam ter este formato:
- ID único do device
- Latitude
- Longitude
- Timestamp (data e hora)
Sozinhos, eles são apenas registros técnicos de localização cartográfica.
O desafio é agrupar esses pontos de forma inteligente para responder perguntas como:
- “Esse conjunto de pontos representa um local fixo?”
- “Esse local é visitado por outros devices? Na mesma data? Horário?”
- “Esse local é visitado com frequência suficiente para indicar rotina?”
- “Em quais horários esse local aparece?”
- “É um padrão recorrente ou algo pontual?”
É aí que entram as técnicas de clusterização espacial e temporal com uso de metodologia estatística e probabilística.
Uma das abordagens possíveis: DBSCAN
Existem várias formas de agrupar dados de geolocalização e uma delas, bastante conhecida, utilizada e eficiente, é o DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
Apesar do nome técnico, a ideia por trás dele é simples, o DBSCAN agrupa pontos que:
- Estão geograficamente próximos
- Aparecem com densidade suficiente
- Se repetem ao longo do tempo
E ele faz isso sem precisar que você diga antes quantos grupos existem e isso ajuda a identificar padrões e locais que não eram inicialmente conhecidos, ajudando a entender tendências antes mesmo que fiquem evidentes à olho nu.
Isso é especialmente importante quando falamos de comportamento humano, porque:
- As pessoas não têm um número fixo de lugares
- Algumas rotinas são claras, outras são mais difusas
- Sempre existem exceções, mas que podem ser relevantes (shows, eventos etc)
Como isso se aplica a moradia, trabalho e visitas?
Vamos trazer isso para um contexto prático.
1. Inferência de moradia
Em geral, um local de moradia apresenta padrões como:
- Alta recorrência
- Presença majoritária à noite
- Frequência durante finais de semana
- Permanência prolongada
Quando aplicamos uma técnica como o DBSCAN:
- Os pontos noturnos e recorrentes tendem a formar um cluster denso
- Pontos isolados (ruído) são descartados
- O cluster mais consistente nesse contexto pode ser inferido como provável local de moradia
Nada disso é uma “certeza absoluta” — é uma inferência estatística, baseada em padrão.
2. Inferência de trabalho
O raciocínio é parecido, mas o padrão muda:
- Presença recorrente em dias úteis
- Horários comerciais
- Menor frequência noturna
- Permanência concentrada durante o dia
O DBSCAN ajuda a identificar:
- Um cluster distinto do de moradia
- Com comportamento temporal diferente
- Com alta regularidade semanal
Isso permite inferir um provável local de trabalho, sem precisar que o usuário diga onde trabalha.
3. Lugares visitados e hábitos de consumo
Nem todo cluster é moradia ou trabalho e aí o DBSCAN pode ajudar ainda mais.
Alguns agrupamentos indicam:
- Academias
- Restaurantes
- Shoppings
- Hospitais
- Escolas
- Pontos de lazer
Aqui, o DBSCAN é útil porque:
- Identifica clusters mesmo com menor frequência
- Mantém pontos isolados como “ruído”
- Ajuda a separar rotina de evento pontual
Esses clusters alimentam análises como:
- Afinidade com categorias
- Hábitos de deslocamento
- Perfil comportamental urbano
Por que DBSCAN é uma das principais metodologias utilizadas para auxiliar a definição de GeoBehavior?
Em projetos com dados de geolocalização, o DBSCAN costuma ser interessante porque:
- Não exige número pré-definido de clusters
- Lida bem com ruído (dados esporádicos)
- Funciona bem em ambientes urbanos densos
- Se adapta melhor à imprevisibilidade do comportamento humano
Isso não significa que ele seja a única solução — mas sim uma alternativa robusta dentro de um conjunto maior de técnicas.
Na prática, projetos maduros costumam combinar:
- Regras de negócio
- Janelas temporais
- Clusterização espacial
- Validações estatísticas
- Camadas de privacidade e anonimização
Importante: inferência não é identificação
Um ponto essencial, e que vale reforçar:
Inferir comportamento não é identificar uma pessoa.
Essas análises trabalham com:
- Dados anonimizados
- Padrões agregados
- Probabilidades, não certezas individuais
O foco está em entender comportamento coletivo, gerar inteligência e apoiar decisões, sempre respeitando princípios de privacidade e conformidade regulatória.
Conclusão
Dados de geolocalização ganham valor quando deixam de ser pontos isolados e passam a revelar padrões de vida urbana.
Técnicas como o DBSCAN ajudam justamente nisso:
- Transformar volume em significado
- Separar rotina de exceção
- Apoiar inferências como moradia, trabalho e hábitos
No fim, o mais importante não é a técnica em si, mas como ela é usada, combinada e interpretada dentro de um contexto responsável e estratégico.
Se quiser saber mais sobre a metodologia DBSCAN ou como utilizar GeoBehavior no seu negócio, entre em contato com nosso time de especialistas.



O Brasil voltou a mostrar em Cannes uma força que vai além da criatividade pela criatividade. Os cases premiados combinam cultura, mídia, tecnologia, comportamento e ideias simples de entender, exatamente o tipo de construção que transforma campanhas em conversa.
O principal destaque foi “Cupom em Campo”, da GUT São Paulo para Mercado Livre, vencedor do Grand Prix em Outdoor. A campanha transformou o gramado do Pacaembu em um código de barras gigante, permitindo que o público escaneasse a imagem durante a transmissão de uma partida e acessasse descontos em tempo real.
A LePub também levou Ouro com “Podia ser uma Heineken”, campanha criada para Heineken que conectou mídia exterior, comportamento social e o convite para encontros presenciais. Já a VML conquistou Ouro com “The Last Coke in the Desert”, para Coca-Cola, ao valorizar pequenos comerciantes que mantêm a bebida gelada mesmo em regiões remotas.
Na área de Health & Wellness, a Publicis Brasil foi premiada com “Save the Day”, para o Grupo Pulsa, iniciativa que transformou o dia de folga após a doação de sangue em uma oportunidade para jogar, aproximando a causa do universo gamer.
A Africa Creative também apareceu entre os Ouros com “Searching for Birds on Wires”, para Abradee, usando o áudio como ferramenta para chamar atenção aos riscos enfrentados por aves em fios elétricos.
Outro destaque veio em Design, com “Dancebook Brasil”, da Lovely para Bradesco, projeto que registrou danças brasileiras em partituras coreográficas, preservando movimentos culturais como samba, frevo, toada e chula.
Mais do que celebrar troféus, os cases brasileiros mostram uma direção importante: criatividade premiada hoje não vive só da grande ideia. Ela precisa conectar contexto cultural, uso inteligente de mídia, comportamento real e uma execução simples o suficiente para ser entendida rápido e forte o suficiente para circular.


O Creative Data Lions surgiu em 2015 como resposta a uma mudança de mercado: o dado deixava de ser camada de mensuração para virar matéria-prima de criação, de produtos, serviços e experiências, não só de argumento de campanha.
A categoria nasceu para reconhecer trabalhos em que dados, tecnologia, estratégia e criatividade atuam juntos para gerar impacto real. Não basta usar dado como prova de resultado. O ponto é mostrar como a inteligência de dados pode ser a base da própria ideia, o esqueleto, não a maquiagem.
Logo no primeiro ano, a categoria recebeu 609 inscrições e premiou 28 trabalhos. O júri decidiu não dar Grand Prix naquela edição, justamente por entender que a régua ainda estava sendo desenhada.O Brasil apareceu com um Leão de Bronze para “Meeting Murilo“, da Huggies/Kimberly-Clark (agência Mood).
O primeiro Grand Prix só veio na edição seguinte, em 2016: “The Next Rembrandt“, para o ING, criado pela J. Walter Thompson Amsterdam, um quadro impresso em 3D, treinado com dados de 346 pinturas originais de Rembrandt, que também levou o Grand Prix de Cyber no mesmo ano.
Para nós da Hands, Creative Data sempre foi a parte da premiação com maior expectativa, não pelo tema em si, mas porque conversa direto com como enxergamos mídia, comportamento e tecnologia: dado não como fim, mas como infraestrutura para criar contexto, resolver problema e gerar ação.
Em 2026, a categoria recebeu 391 inscrições e premiou 13 cases: 1 Grand Prix, 2 Ouros, 4 Pratas e 6 Bronzes. O Brasil chegou com 5 finalistas e converteu 2 Leões, Prata para “Unwatched Goals“, da Africa Creative para a Brahma, e Bronze para “Nigrum Corpus“, da Artplan para IDOMED e Instituto Yduqs (que também levou o Grand Prix de Glass: The Lion for Change nesta edição, tornando-se a primeira campanha brasileira a vencer dois Grand Prix diferentes na história do festival).
O Grand Prix mostrou onde a régua está agora
O Grand Prix de Creative Data 2026 foi para “SOS POS“, criado pela Circus Grey Lima para o BCP, o maior banco do Peru. E o que esse case prova é o oposto do que a maioria do mercado assume sobre “dado criativo”: não é sobre complexidade, é sobre encontrar um problema e entender como o uso inteligente de dados pode resolvê-lo, nesse caso ainda com o brilhantismo de utilizar uma infraestrutura já existente.
O ponto de partida é um problema concreto: no Peru, mais de 4 mil celulares são roubados por dia. O ladrão desbloqueia o aparelho em minutos e esvazia contas pelos apps bancários antes que a vítima consiga reagir. Todo banco tem linha de emergência para bloqueio, mas como ligar sem o celular? A pessoa depende de pedir emprestado, ou correr até uma agência, perdendo os minutos que mais importam.
A resposta do BCP não foi criar um canal novo, foi reaproveitar uma infraestrutura que já está em praticamente toda esquina: a maquininha de cartão. O POS (máquina de cartão de crédito) deixou de ser só ponto de venda e virou ponto de bloqueio de emergência. A vítima vai até o comércio mais próximo, digita documento e senha em qualquer maquininha participante, e a conta é bloqueada na hora, sem app, sem ligação, sem depender do aparelho roubado. O banco mapeou as regiões de maior incidência de furto e instalou mais de 17,5 mil pontos de bloqueio, cada um a menos de dois minutos de distância, com meta de chegar a 120 mil ao longo de 2026.
O que faz esse case ser forte em Creative Data não é sofisticação técnica, é o contrário disso. A ideia usa dados de localização (onde o roubo acontece mais), dado de autenticação (documento + senha) e uma rede física já madura (a malha de POS) para resolver, em minutos, um problema que hoje custa horas. Simples, rápido, escalável, e sem inventar nenhuma tecnologia nova. A criatividade estava em reconhecer que o dado certo já existia dentro de um sistema que ninguém tinha pensado em usar daquele jeito.
É a mesma lógica que sustenta qualquer estratégia de segmentação geolocalizada: o valor não está em coletar mais dados, está em reconhecer o padrão que já está ali, visita, frequência, permanência e transformar isso em ação no momento certo. O SOS POS não inventou uma nova camada de dado. Ele leu o que já tinha, e resolveu um problema real com ela.


A Hands esteve na 73ª edição do Cannes Lions, o principal festival internacional de criatividade. Realizado anualmente na Riviera Francesa, o evento reúne agências, anunciantes, produtoras, big techs, creators, plataformas e lideranças que ajudam a definir os próximos movimentos da indústria.
Em 2026, o festival recebeu mais de 13 a 15 mil profissionais de mídia, tecnologia e publicidade de mais de 90 países, além de mais de 500 speakers e 150 horas de conteúdo ao longo da semana. Na premiação, foram 20.050 inscrições vindas de 92 países, queda de 25,46% em relação às 26.900 inscrições de 2025. A redução veio no mesmo ano em que o Cannes Lions adotou padrões mais rígidos de integridade para as inscrições, em resposta a debates sobre autenticidade, uso de IA, resultados inflados e transparência dos cases.
Nesta edição, a maior expectativa era entender como a inteligência artificial entraria na pauta depois de um 2025 marcado por debates, excessos e dúvidas sobre seu impacto real na criatividade, nos negócios e na operação de marketing.
Ao longo da semana, ficou claro que a discussão sobre IA já não é mais uma discussão sobre novidades. O tema apareceu conectado à criatividade, produtividade, reputação, cultura, confiança e, principalmente, à capacidade das marcas de manterem relevância em um ambiente cada vez mais automatizado.
Demis Hassabis, cofundador e CEO do Google DeepMind, dimensionou a escala da mudança em conversa no palco do Palais: nos próximos 10 a 15 anos, disse ele, a IA pode inaugurar “quase uma nova era humana”. A fala ajuda a entender por que o tema deixou de ser tendência lateral e virou centro da agenda, mas também é bom lembrar que é a visão de quem lidera um dos laboratórios que mais lucra com essa aceleração. Vale ouvir, não vale comprar sem checar.
Byron Sharp, do Ehrenberg-Bass Institute, maior centro de pesquisa de marketing do mundo, localizado na University of South Australia, e escritor do livro How Brands Grow (Como as Marcas Crescem), puxou a conversa de volta pra disciplina, dividindo palco com Mark Ritson numa sessão que lotou o Debussy Theatre. O ponto central deles: o trabalho de marca não é sobre o que a marca significa, é sobre o que evoca a marca, ativos distintivos, repetidos sem cansar, por tempo suficiente pra virarem atalho de memória. A provocação prática foi: todo mundo diz acreditar em consistência, mas a maioria das marcas muda de assinatura visual, tom e formato antes mesmo do público reparar que aquilo virou reconhecível. Automação e produção em massa de conteúdo turbinam exatamente esse problema, geram mais variação, não mais consistência.
Onde a conversa humana virou vantagem competitiva
Laura Nestler, EVP de Community do Reddit, levou a discussão para outro território: num mundo saturado de conteúdo gerado por IA, a conversa humana real, estranha, contraditória, imperfeita, passa a carregar sinal que nenhum modelo sintetiza de graça. É por isso que o Reddit chegou a Cannes 2026 vendendo justamente isso como diferencial de plataforma: inteligência de comunidade que “máquinas sozinhas não replicam”. Não é discurso sobre autenticidade, é posicionamento comercial direto contra o excesso de conteúdo gerado por IA que está inundando todo o resto da internet.
Asmita Dubey, Chief Digital & Marketing Officer da L’Oréal, trouxe um dado difícil de ignorar: hoje existem meio milhão de pessoas falando em nome das marcas da L’Oréal de forma autêntica, os creators. E ela também apontou pra onde a disputa está indo em seguida: como LLMs viram a nova porta de entrada pra descoberta de produto, a pergunta que toda marca vai precisar responder é se ela está sendo citada na “camada de resposta” desses modelos, o novo campo de batalha de SEO, só que sem clique, sem página, sem controle editorial da marca sobre o que é dito.
Tessa Lyons, VP de Produto do Instagram, esteve no palco da Rotonde com o artista Daniel Arsham, que cria esculturas e instalações surrealistas que transformam objetos modernos do nosso quotidiano como carros, consoles de videogames e personagens da cultura pop em artefatos desgastados pelo tempo, utilizando materiais como cinza vulcânica, selenita, quartzo e cristal. O papo abordou como ferramentas de IA podem ampliar repertório e velocidade de produção, mas sem que isso substitua a intenção criativa humana por trás da ideia. O deslocamento que a sessão propôs foi menos “IA substituindo pessoas” e mais “como ferramentas escalam produção sem esvaziar critério”.
Oprah Winfrey, apresentadora, produtora, empresária e uma das maiores personalidades da mídia global, foi homenageada com o Cannes LionHeart 2026, uma das principais distinções do festival para lideranças que usam criatividade, influência e voz pública para gerar impacto positivo. Em conversa com Phil Thomas, chairman do Cannes Lions, no Lumière Theatre, ela levou a discussão para intenção, confiança e legado. A frase que resume o tom da participação foi “my heart is my brand”: a ideia de que marca forte não nasce apenas de alcance, consistência visual ou presença midiática, mas de uma verdade reconhecível por trás de tudo o que se comunica.
REC Maison by Hands
A nossa presença em Cannes foi além da agenda “oficial” do Festival e contou com um espaço especial na Riviera Francesa.
Em parceria com o Reclame e o Multishow marcamos presença com a REC Maison by Hands, uma casa aonde recebemos clientes, parceiros e profissionais do mercado para cafés, drinks e conversas ao longo da semana.
O grande momento da Maison foi o dia do jogo do Brasil vs Escócia, no qual recebemos mais de 300 pessoas para torcer juntas pelo Brasil em pleno território francês. E acho que deu sorte heim!

Confira mais sobre a Rec Masion by Hands aqui e aqui.
Cobertura Hands + Reclame / Multishow
Além dos encontros presenciais, a Hands também esteve conectada à cobertura do Reclame no Multishow, acompanhando bastidores, entrevistas e análises sobre os principais acontecimentos do Cannes Lions.

Cannes 2026 repetiu “IA” em todo palco relevante. Mas o padrão dos cases premiados foi outro: quando qualquer marca produz volume infinito com um prompt, volume vira o mínimo esperado, não vantagem. O Grand Prix de Creative Data não foi pra quem coletou mais dados, foi pra quem reconheceu o dado certo dentro de uma infraestrutura que ninguém tinha pensado em reaproveitar. É a mesma lógica que sustenta tudo o que a Hands faz: a vantagem não está em produzir mais, está em provar que o dado é comportamento real, não simulação.
Quatro pontos se destacaram: (1) a criatividade segue central, mas precisa estar cada vez mais conectada a contexto e aqui que os dados podem fazer a diferença; (2) o dado deixou de ser apenas ferramenta de segmentação e passou a ser infraestrutura para sustentar a tese dos projetos e cases; (3) comunidades estão ganhando mais peso do que recortes demográficos genéricos e (4) a inteligência artificial já começa a ocupar a operação de mídia, distribuição e otimização, mas ainda não substitui a criatividade, sendo na verdade uma ferramenta que precisa ser considerada para dar maior escala, customização e experiência para as idéias.
-

 Geobehavior8 meses ago
Geobehavior8 meses agoAudience Hub: como funciona a tecnologia por trás da segmentação precisa da Hands
-

 Outros1 ano ago
Outros1 ano agoBem-vindo ao Hands Academy
-

 Outros1 ano ago
Outros1 ano agoConfira os detalhes do último Hands Quiz!
-
 Geobehavior1 ano ago
Geobehavior1 ano agoOOH + Estratégias Mobile
-

 Outros1 ano ago
Outros1 ano agoSegmentação Geográfica com Polígonos: maior precisão, melhores resultados
-

 Geobehavior1 ano ago
Geobehavior1 ano agoGeoBehavior como segmentação de Mídia Digital
-

 Hands Quiz11 meses ago
Hands Quiz11 meses agoHash: o que é, como funciona e porque quem trabalha com marketing digital precisa conhecer.
-

 Geobehavior1 ano ago
Geobehavior1 ano agoGeolocalização + Plataformas Digitais (DSPs e Ad Managers)