
Dados & Estratégia
Amostra Estatística em Marketing Digital: o que está por trás das audiências que você usa todo dia
Meta description: Entenda como a amostra estatística em marketing digital define a qualidade das suas audiências — e o que separa uma segmentação confiável de um chute bem embalado.

Toda campanha de mídia digital começa com uma pergunta que quase ninguém faz em voz alta:
Essa audiência representa quem eu acho que representa?
Na maioria das vezes, a resposta honesta seria: não sei. E isso tem um nome técnico, erro amostral. O problema é que o mercado de mídia programática trata audiências como fatos consolidados, quando muitas delas são, na melhor das hipóteses, estimativas estatisticamente frágeis.
Entender amostra estatística em marketing digital não é exercício acadêmico. É o que separa uma decisão de investimento embasada de uma aposta com linguagem técnica.
O que é amostra estatística e por que isso importa para quem compra mídia
Em estatística, população é o conjunto completo de elementos que você quer estudar. Amostra é o subconjunto que você consegue de fato observar.
No contexto de mídia digital, a população seria o universo total de pessoas que você quer atingir, todos os consumidores de uma categoria, todos os frequentadores de um tipo de estabelecimento, todos os decisores de compra de um segmento. A amostra é o grupo que sua plataforma de audiência conseguiu identificar e segmentar.
O que poucos param para avaliar: qual é a relação entre esses dois números? Se você quer atingir 500 mil pessoas e sua audiência tem 12 mil devices, o que essa audiência realmente representa? Ela é suficientemente grande? Ela foi construída com critérios que garantem representatividade? Ou ela captura apenas a fração mais acessível e não necessariamente a mais relevante?
Essas perguntas não são apego exagerado a estatistica. Elas determinam se o resultado da sua campanha vai refletir a realidade do mercado ou um viés que você não sabia que existia.
As três dimensões de qualidade que toda audiência precisa responder
Antes de ativar qualquer segmentação, independente da plataforma ou da fonte de dados, existem três dimensões que determinam se você está trabalhando com uma audiência estatisticamente sólida ou com uma que vai gerar conclusões difíceis de interpretar.
1. Volume em relação ao universo-alvo
Existe um limiar mínimo abaixo do qual qualquer resultado de campanha é estatisticamente inconcluso. Uma audiência muito pequena em relação à população que se propõe a representar amplifica o efeito de comportamentos atípicos e pode distorcer completamente a leitura de performance.
O tamanho adequado depende de dois fatores: o quanto a população-alvo é heterogênea em comportamento, e o nível de confiança que você precisa nas conclusões. Não existe número universal, mas o princípio é consistente: quanto mais diverso o comportamento da população que você quer atingir, maior precisa ser a audiência para representá-la com fidelidade.
A pergunta prática não é só “quantos devices tem essa audiência?” mas “quantos devices tem essa audiência em relação ao universo real que ela pretende representar?”
2. Origem e processo de construção
A forma como uma audiência é construída determina quem ela captura bem e quem ela sistematicamente deixa de fora. Audiências baseadas em dado declarado capturam quem se dispõe a declarar. Audiências baseadas em um único tipo de fonte de dados refletem as características dos usuários daquela fonte, não necessariamente da população total.
Isso não é um defeito de nenhuma metodologia específica, é uma propriedade estrutural de qualquer processo amostral. O que importa é conhecer o critério de construção para entender os limites da representatividade. Uma audiência construída com critérios transparentes e documentados permite que você use os resultados com o nível de confiança adequado. Uma audiência construída como caixa-preta não.
3. Aderência geográfica e temporal ao contexto da campanha
Uma audiência construída com dados de uma região pode não se comportar da mesma forma que a população de outra, mesmo com perfil demográfico similar. Padrões de deslocamento, frequência de visita a estabelecimentos, tempo de permanência, tudo isso varia geograficamente de formas que dados agregados não mostram.
O eixo temporal tem o mesmo peso: uma audiência capturada numa janela sazonal específica carrega o comportamento daquele período. Usá-la fora desse contexto sem considerar essa variável é introduzir um erro que nenhum algoritmo de otimização vai identificar, porque ele não sabe que o problema existe.
Quando a amostra deixa de ser amostra: o caso dos dados comportamentais passivos
Aqui está o ponto que muda a conversa.
A lógica amostral tradicional, selecionar um subgrupo para inferir o comportamento do todo, existe por uma razão prática: coletar dados de toda a população é inviável. Você não consegue entrevistar 50 milhões de consumidores. Você não consegue observar todos os comportamentos de compra em tempo real.
Mas quando falamos de dados de geolocalização comportamental coletados passivamente, a lógica muda.
Um polígono geográfico, a delimitação exata de um shopping, de um aeroporto, de uma avenida, de uma área residencial, garante que apenas os dispositivos detectados dentro daquela área específica entram na audiência. Não há extrapolação de raio, não há contaminação de passantes fora do contexto. O que é capturado, é capturado com precisão de contorno.
Isso não é uma amostra no sentido estatístico clássico. É uma captura censitária dentro de um universo definido.
A diferença prática é significativa: você não está inferindo quantas pessoas frequentam aquele aeroporto, nem estimando com margem de erro qual é o perfil de quem visita aquela avenida. Você está trabalhando com o registro comportamental real, hora de chegada, tempo de permanência, frequência de retorno, padrão de dias da semana, de todos os dispositivos detectados naquele espaço.
Isso elimina os dois principais problemas de amostragem discutidos acima: o viés de seleção (porque o critério de inclusão é puramente geográfico e comportamental, não demográfico ou declarado) e a não representatividade (porque a audiência é a população daquele comportamento naquele espaço, não uma estimativa dela).
O que resta como limite não é mais estatístico, é de cobertura. Qual percentual do universo de dispositivos reais está dentro do banco de dados da plataforma? Essa é a pergunta certa a fazer. E a resposta varia muito dependendo da fonte de dados e da metodologia de coleta.
Amostra estatística em marketing digital na prática
Considere uma marca de produtos de higiene pessoal que quer ativar uma campanha para consumidores de supermercados premium em três capitais brasileiras.
Abordagem A — audiência por dados declarados: A plataforma constrói uma audiência baseada em perfil demográfico e interesse autodeclarado. 180 mil devices. O problema: quem declara interesse em “produtos premium” num formulário ou numa navegação web não é necessariamente quem entra num supermercado premium toda semana. A audiência é uma amostra com viés de seleção enorme, captura quem pensa que compra nesse canal, não quem efetivamente compra.
Abordagem B — audiência por comportamento geolocalizado: A plataforma delimita os polígonos exatos das unidades dos supermercados premium nas três capitais. Detecta todos os dispositivos que estiveram presentes dentro desses polígonos pelo menos duas vezes no último trimestre, com tempo de permanência mínimo de 20 minutos, o que elimina passantes e funcionários. Resultado: 94 mil devices.
O número é menor. Mas o que esses 94 mil devices têm em comum é um comportamento verificado, não uma declaração. A “amostra” aqui não é uma estimativa de quem frequenta supermercados premium, ela é o registro de quem frequentou, dentro do universo de cobertura da plataforma.
Para a marca, a pergunta relevante não é “qual audiência tem mais volume?” mas “qual audiência está mais próxima da população real que eu quero atingir?” e a resposta muda o critério de avaliação de qualidade de audiência completamente.
O que perguntar antes de confiar em qualquer audiência
Se você é responsável por decisões de mídia e quer aplicar o raciocínio de amostra estatística no dia a dia, essas são as perguntas que valem fazer antes de ativar qualquer segmentação:
Sobre o universo:
- Qual é a população real que esta audiência deveria representar?
- Existe alguma estimativa do tamanho total dessa população para comparar com o volume da audiência?
Sobre o processo de construção:
- Qual foi a fonte dos dados? Declarado, comportamental passivo, inferido por modelo?
- Qual foi a janela temporal de coleta? Ela é compatível com o comportamento que você quer capturar?
- Existe algum critério de seleção que pode estar sistematicamente excluindo um subgrupo relevante?
Sobre os limites:
- Qual é a cobertura geográfica real da fonte de dados?
- A audiência foi construída com dados de uma única fonte ou com dados enriquecidos de múltiplas origens?
Não existe audiência perfeita. Existe audiência cujos limites você conhece e audiência cujos limites você ignora. A diferença entre as duas não está no CPM, está na capacidade de interpretar corretamente o que a performance da campanha está te dizendo.
Conclusão: amostra estatística em marketing digital não é teoria, é critério de compra
O mercado de mídia digital evoluiu muito na capacidade de criar e ativar audiências. Evoluiu menos na cultura de questionar a qualidade estatística dessas audiências antes de investir nelas.
Entender amostra estatística em marketing digital é, na prática, desenvolver um critério mais rigoroso para avaliar o que você está comprando quando compra uma audiência. É a diferença entre otimizar uma campanha dentro de um viés que você não sabe que existe e tomar decisões com dados que têm correspondência real com o comportamento de mercado.
A tecnologia de dados comportamentais passou por uma mudança de paradigma nos últimos anos. A capacidade de capturar comportamento real, onde as pessoas vão, com que frequência, por quanto tempo, sem depender de dado declarado ou de inferência demográfica, aproxima a audiência digital do censo comportamental e afasta do problema clássico de amostragem.
Conhecer essa diferença é o que permite usar audiências com a precisão que elas oferecem e não com a imprecisão que você não sabia que estava aceitando.
Quer entender como os dados de geolocalização comportamental da Hands são construídos e como isso afeta a qualidade das audiências que você ativa? Fale com nosso time.



Dados & Estratégia
Model Context Protocol (MCP): por que o contexto virou a camada mais crítica da IA
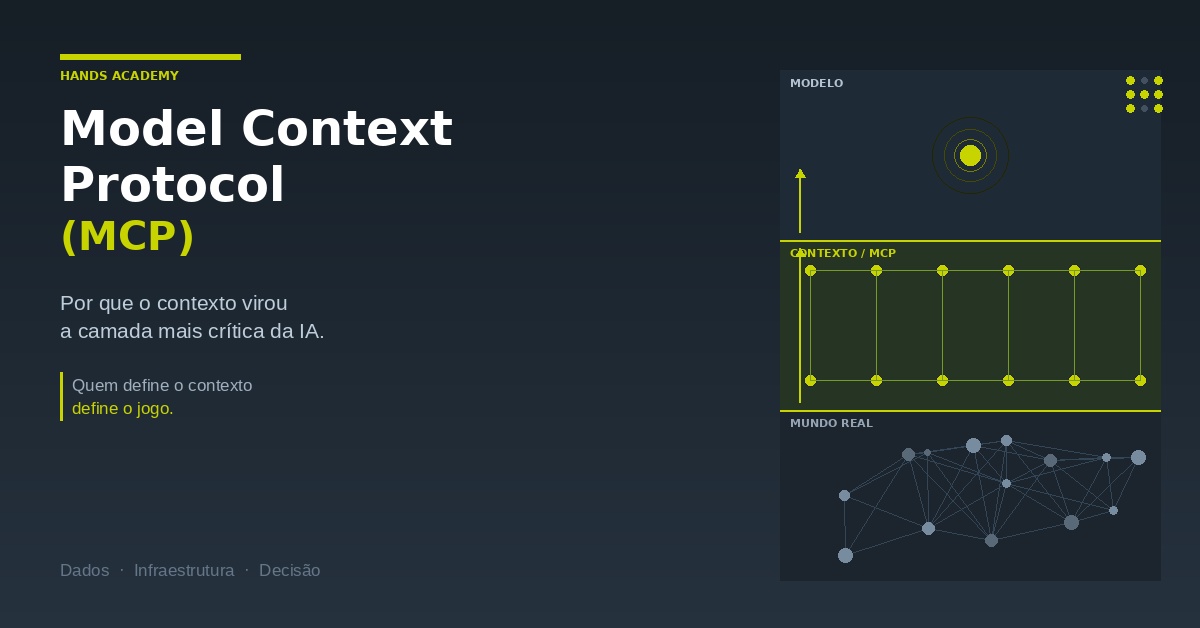
O Model Context Protocol (MCP) é um padrão que define como modelos de IA acessam dados, ferramentas e sistemas externos de forma estruturada. Na prática, ele cria uma camada intermediária entre o modelo e o mundo real. Em vez de depender de integrações pontuais ou de contexto “injetado” via prompt, o modelo passa a operar sobre recursos organizados, com regras claras de acesso e formatos definidos.
Isso resolve um problema que até agora vinha sendo tratado de forma improvisada: o acesso ao contexto. E aqui está o ponto que muda o nível da discussão.
A maior parte das conversas sobre IA em mídia ainda gira em torno de modelo, prompt e automação. Isso é confortável. É tangível. Dá pra testar rápido. Mas não é onde o sistema quebra.
O modelo só responde ao que ele consegue acessar. E hoje, esse acesso, o contexto, ainda é a parte mais frágil de toda a arquitetura. Então não, o problema não é inteligência.
O problema é o que alimenta essa inteligência.
O modelo não erra sozinho. Ele erra com o contexto que você deu.
Quando uma IA entrega uma resposta ruim, a reação padrão é culpar o modelo. Só que na prática, o erro quase sempre está antes. O modelo depende de três coisas para operar fora do seu próprio conhecimento: descobrir dados, acessar esses dados e interpretar corretamente o que recebeu.
Hoje, essas três camadas são resolvidas de forma improvisada.
Cada integração é única. Cada fonte de dado chega em um formato diferente. Cada uso exige adaptação manual. Isso cria um cenário previsível: inconsistência, baixa confiança e decisões que parecem certas, até não serem. Então não é que o modelo “alucina”. Ele só está operando em cima de um contexto mal estruturado.
O MCP entra exatamente onde o sistema quebra
Se o problema está no acesso ao contexto, melhorar o modelo não resolve. O MCP resolve. Ele padroniza como dados, ferramentas e sistemas são expostos para o modelo. Isso significa que o modelo não precisa mais “adivinhar” o que existe ou como usar. Ele passa a operar sobre interfaces claras.
Na prática, isso elimina três fricções estruturais: o modelo passa a saber o que está disponível, como acessar e como interpretar.
Ou seja, o que antes era improviso vira arquitetura.
Contexto deixou de ser input. Virou infraestrutura.
Aqui está a mudança que a maioria ainda não entendeu. Hoje, contexto é tratado como algo que você injeta no prompt. Um apoio. Um complemento. Com MCP, contexto vira base operacional.
Os dados deixam de ser texto solto e passam a ter estrutura. As ferramentas deixam de ser chamadas improvisadas e passam a ter função definida. O acesso deixa de ser aberto e passa a ser governado. Isso muda completamente o tipo de problema que pode ser resolvido. Sem estrutura, IA responde. Com estrutura, IA opera.
Esse movimento já aconteceu na mídia
Durante muito tempo, a segmentação em mídia digital foi construída dentro das próprias plataformas.
Google, Meta, DV360. Cada ambiente definia quais dados estavam disponíveis, como esses dados eram organizados e quais critérios podiam ser usados para segmentação. Na prática, isso criava uma dependência total da lógica de cada canal.
Se a estratégia fosse impactar pessoas com determinado comportamento — como frequentadores de shopping ou visitantes de uma rede de lojas — essa definição ficava limitada à interpretação da própria plataforma, geralmente baseada em proxies frágeis como interesse declarado ou navegação. Isso funcionava enquanto o objetivo era escala.
Mas começou a quebrar quando o mercado passou a exigir precisão, consistência entre canais e maior controle sobre quem estava sendo impactado. O ponto de ruptura veio quando duas pressões começaram a acontecer ao mesmo tempo.
De um lado, a perda de sinal e as restrições de privacidade reduziram drasticamente a qualidade e a granularidade dos dados dentro das plataformas. Do outro, a operação de mídia ficou mais complexa, exigindo consistência de audiência entre múltiplos canais.
Nesse cenário, depender do dado nativo de cada plataforma deixou de ser solução e passou a ser problema. A mesma audiência era definida de formas diferentes em cada canal. Não havia garantia real de quem estava sendo impactado. E qualquer tentativa de integração virava adaptação manual.
A resposta do mercado não foi melhorar o uso das plataformas. Foi tirar a construção de audiência de dentro delas. Começaram a ganhar espaço estruturas como CDPs, DMPs e hubs de audiência, onde a lógica muda completamente: a audiência deixa de ser o que a plataforma permite e passa a ser um ativo estruturado antes da ativação.
Em vez de trabalhar com categorias genéricas como “interesse em varejo”, passa a ser possível definir audiências com base em comportamento real, como pessoas que visitaram lojas específicas, com frequência mínima e dentro de um determinado período.
Esse tipo de construção não nasce no canal. Ele nasce fora e depois é distribuído.
O ganho aqui não é incremental. É estrutural.
Você separa o dado do canal. Define quem impactar independentemente de onde vai impactar. Garante consistência entre plataformas. E deixa de depender da inteligência limitada de cada ambiente de mídia.
E é exatamente esse tipo de separação que o MCP começa a introduzir no universo de IA.
Hoje, muitos modelos ainda operam presos ao contexto que conseguem acessar diretamente, seja via prompt, integrações pontuais ou conexões específicas. Isso é equivalente à lógica antiga da mídia, onde a decisão dependia do ambiente.
Com MCP, o contexto passa a ser estruturado fora do modelo. Fontes são definidas, acessos são padronizados e o modelo passa a consumir esse contexto de forma organizada.
O paralelo aqui não é conceitual. É operacional. Assim como a mídia evoluiu quando separou dado de canal, a IA começa a evoluir quando separa contexto de modelo.
A Hands já opera nessa lógica mesmo sem chamar de MCP
Quando a Hands estrutura audiência, ela já está resolvendo um problema que o mercado ainda tenta empurrar para as plataformas. No Audience Hub, por exemplo, a audiência não nasce limitada por canal. Ela é construída com base em comportamento real, com granularidade de localização e filtros que as plataformas não oferecem. Depois, ela é distribuída para onde fizer sentido ativar .
Isso é mais do que segmentação. É organização de contexto antes da execução.
Agora conecta isso com MCP e o nível muda
Se hoje a audiência é usada para ativação, com MCP ela passa a ser usada para decisão. Porque ela pode ser exposta como um recurso estruturado. Isso significa que sistemas, não só campanhas, podem consumir esse dado. O que antes era “quem impactar” vira “como decidir”. E isso desloca completamente o papel da mídia dentro da operação.
Quando contexto vira protocolo, execução vira commodity
Aqui está o ponto que pouca gente está preparada para encarar. Se o acesso ao contexto é padronizado, o modelo deixa de ser diferencial. Se a ativação é multicanal e interoperável, o canal deixa de ser diferencial. Se a execução pode ser automatizada, a operação deixa de ser diferencial.
O que sobra?
A estrutura do contexto. Quem organiza melhor o dado antes da decisão passa a ter vantagem estrutural. Não incremental. Estrutural.
Quem ainda está discutindo campanha já está atrasado
O mercado ainda está focado em otimizar campanha. Melhor criativo, melhor segmentação, melhor performance. Tudo isso continua importante, mas está um nível abaixo do que está mudando. A nova camada não é execução. É decisão. E decisão depende de contexto.
No fim, MCP não muda a IA. Muda quem manda nela.
Se antes a pergunta era “qual modelo usar”, agora passa a ser outra:
quem define o contexto que esse modelo acessa?
Porque no limite, é isso que determina:
- o que entra na análise
- o que é ignorado
- e qual decisão é possível
E aí não estamos mais falando de tecnologia. Estamos falando de controle. E quem controla o contexto não melhora resultado.
Define o jogo.
-

 Geobehavior7 meses ago
Geobehavior7 meses agoAudience Hub: como funciona a tecnologia por trás da segmentação precisa da Hands
-

 Outros1 ano ago
Outros1 ano agoBem-vindo ao Hands Academy
-

 Outros1 ano ago
Outros1 ano agoConfira os detalhes do último Hands Quiz!
-

 Outros5 meses ago
Outros5 meses agoDBSCAN: a metodologia para o entendimento de comportamento baseado em geolocalização
-
 Geobehavior1 ano ago
Geobehavior1 ano agoOOH + Estratégias Mobile
-

 Outros1 ano ago
Outros1 ano agoSegmentação Geográfica com Polígonos: maior precisão, melhores resultados
-

 Hands Quiz10 meses ago
Hands Quiz10 meses agoHash: o que é, como funciona e porque quem trabalha com marketing digital precisa conhecer.
-

 Geobehavior1 ano ago
Geobehavior1 ano agoGeoBehavior como segmentação de Mídia Digital