
Outros
Segmentação Geográfica com Polígonos: maior precisão, melhores resultados

Não importa se a sua estratégia de geolocalização é baseada em Geofence — considerando pessoas que passam por determinados locais — ou em GeoBehavior, que analisa em detalhes os padrões de visita (data, horário, tempo de permanência frequência etc) e comportamento, o ponto de partida para otimizar sua estratégia está sempre em um mapeamento preciso do local de interesse.
No entanto, a maioria das soluções de mídia geolocalizada ainda trabalha com raios circulares como única forma de definição de área, muitas vezes com restrições de raio mínimo, o que limita bastante a segmentação e reduz sua efetividade. A alternativa para uma estratégia mais eficiente está no uso de polígonos geográficos, disponíveis em algumas plataformas mais avançadas de geolocalização e GeoBehavior.
O que são Polígonos?
Polígonos são formas geográficas personalizadas, desenhadas com exatidão para representar os contornos reais de um local. Pode ser para definir a área de um shopping, um parque, um quarteirão específico, um trecho de rodovia ou qualquer outro local de seu interesse.
Ao invés de estimar a presença com áreas genéricas, que por muitas vezes extrapolam o espaço fisico real dos pontos de interesse, os polígonos permitem segmentar com foco cirúrgico, respeitando os limites reais que importam para a sua estratégia.
Por que usar Polígonos na Segmentação?
- Precisão no mapeamento de locais estratégicos
Ao invés vez de usar um raio de 1km ao redor de um ponto qualquer, é possível desenhar os contornos exatos de uma loja, galeria, avenida ou qualquer ponto de interesse. - Menos dispersão, mais relevância
Com limites mais bem definidos, a mídia é entregue somente para quem realmente esteve ou passou pela área relevante, reduzindo desperdício e aumentando a efetividade. - Comparação e inteligência geográfica
A modelagem com polígonos permite criar e comparar subzonas, entender padrões de comportamento por área e adaptar estratégias com base no que realmente acontece no mundo físico.
Geolocalização e GeoBehavior com Polígonos na prática
O uso de polígonos abre um novo nível de controle e sofisticação na segmentação geográfica — com aplicações diretas em campanhas digitais, mobile e OOH.
Separamos abaixo alguns exemplos práticos de como essa abordagem pode transformar a forma como você cria suas audiências:
Audiência de Frequent Flyers – Aeroporto de Congonhas

Nesta campanha, com foco em criar uma audiência de “Frequent Flyers“, ou seja, pessoas que voaram mais de 4 vezes no período determinado, o polígono permitiu delinear com precisão toda a região do Aeroporto de Congonhas (CGH).
Como aeroporto esta dentro de um centro urbano, cercado de avenidas de grande movimento, o desafio consistia em maximizar o potencial da audiência dentro do aeroporto sem considerar o grande fluxo de passantes na região, principalmente em horários de pico de trânsito.
Audiência de Banhistas – Praia de Ipanema
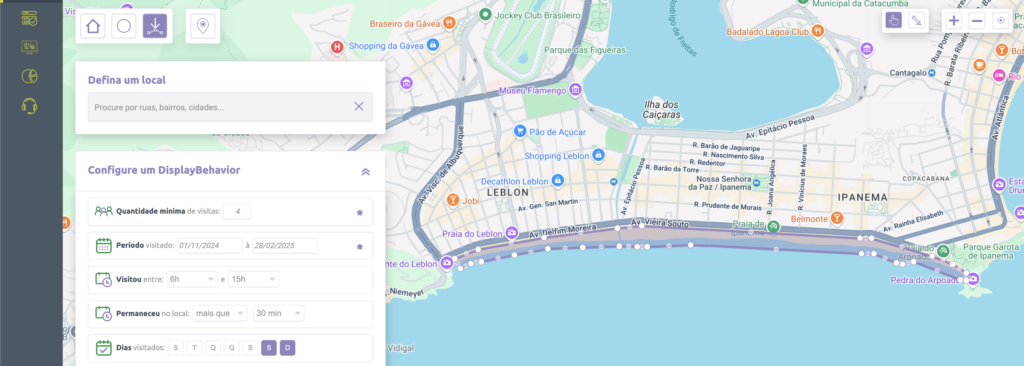
Diversas marcas buscam se relacionar com o publico que frequenta as praias no verão. Mas qual a melhor forma de amplificar ao máximo o potencial desta audiência, sem “vazar” a segmentação? Principalmente em praias em regiões urbanas, nas quais as orlas são cercadas por avenidas de grande fluxo de pessoas.
Na campanha acima, com foco em impactar pessoas que frequentaram a praia no verão de 2024/2025, o uso do polígono permitiu criar audiências específicas na orla de praias de São Paulo e Rio de Janeiro, levando em consideração a demarcação exata do local das praias, não incluindo avenidas ou pontos de maior fluxo fora de contexto, além de considerar outros parâmetros do GeoBehavior, como por exemplo: horário e dia da semana das visitas, além do tempo de permanência nas praias.
Audiência para OOH
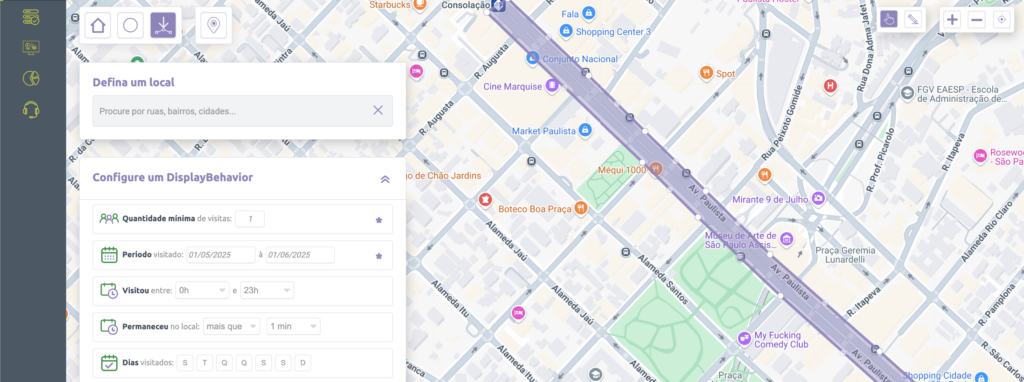
Aproveitar o impacto e awareness do OOH para gerar engajamento e interação em ativações digitais é uma das melhores combinações entre o mundo físico e digital, mas qual a melhor forma de ter ganho de escala sem vazar a mídia fora de contexto?
Neste caso os polígonos podem fazer uma grande diferença, permitindo que sua estratégia de OOH + Mobile tenha como diferencial a capacidade de delinear regiões específicas de circuito de Mídia Out-of-Home. No exemplo acima foi delineada com exatidão a extensão da Av. Paulista em São Paulo, SP, com objetivo de criar uma audiência de quem passou pela avenida com foco em retargeting da campanha OOH em Mobile Ads e Redes Sociais (audiência estendida).
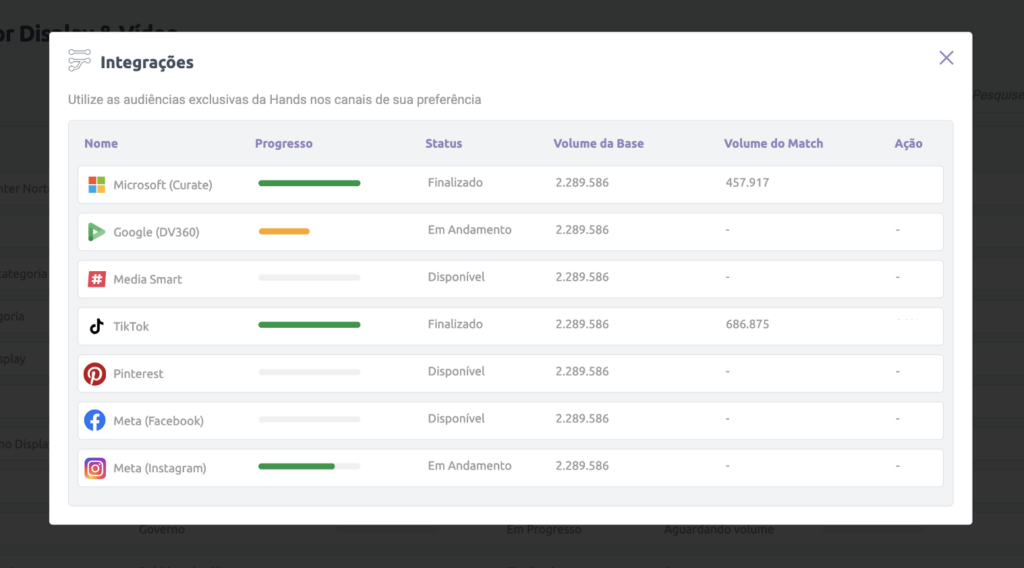
Audiências via Polígonos em qualquer plataforma
Vale relembrar que, através de estratégia de onboarding de audiências, é possível levar as segmentações de geolocalização e GeoBehavior, criadas via polígonos em plataformas especializadas, para serem veiculadas em qualquer canal de mídia dígital ou rede social. Ou seja, você pode levar a audiência exata do Aeroporto de Gongonhas, da Orla de Ipanema, da Av. Paulista, ou qualquer outra de seu interesse, para veiculação aonde fizer mais sentido para a sua campanha; de Push Notification à Media Display, de Instagram à TikTok, de Spotify à Netflix.
Quer saber mais? Fale com nosso time de especialistas: comercial@hands.com.br

Outros
Você sabe qual formato sustenta a sua operação de dados? Conheça o .parquet e entenda por que ele é peça-chave em campanhas de grande escala.
Quando falamos de dados em mídia digital, normalmente pensamos em dashboards, segmentações e plataformas de ativação. Mas existe uma camada anterior a tudo isso: o formato em que esses dados são organizados, armazenados e compartilhados.
E essa camada influencia diretamente escala, velocidade e custo operacional.
Se você trabalha com audiências, geolocalização, dados comportamentais ou exportação multicanal, entender o que é um arquivo .parquet ajuda a compreender como as operações de dados realmente funcionam em larga escala.
O que é, de fato, um arquivo .parquet
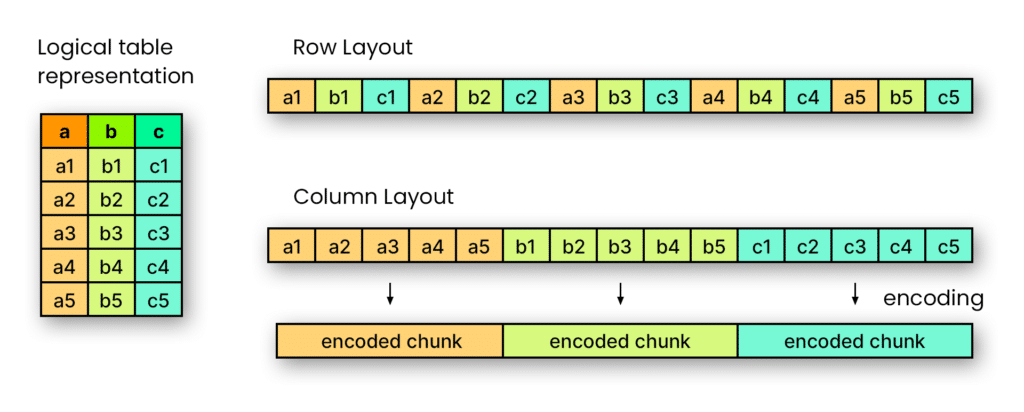
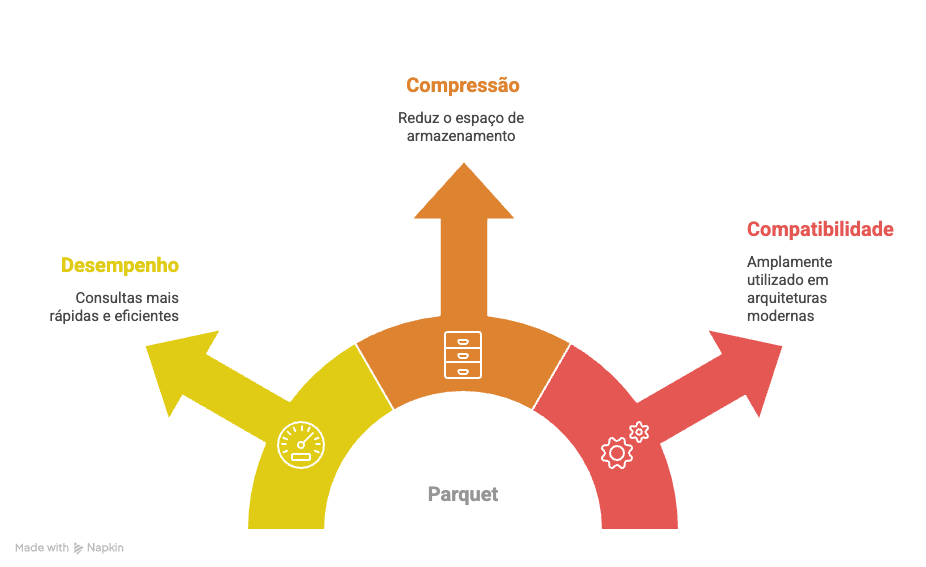
Parquet é um formato de armazenamento colunar criado para ambientes de big data. Ele foi desenvolvido dentro do ecossistema Hadoop e hoje é amplamente utilizado em arquiteturas modernas de dados, como Spark, BigQuery, Snowflake e Data Lakes em geral.
Diferente de formatos como CSV ou JSON, que armazenam os dados linha por linha, o Parquet organiza os dados por coluna.
Isso significa que, em vez de gravar um registro completo de cada usuário em sequência, o arquivo agrupa todos os valores de uma mesma variável juntos.
Por exemplo:
Em vez de armazenar assim:
ID | Data | Local | Permanência | Frequência
ID | Data | Local | Permanência | Frequência
Ele armazena:
Coluna ID
Coluna Data
Coluna Local
Coluna Permanência
Coluna Frequência
Na prática, isso permite que os sistemas leiam apenas os atributos necessários para determinada análise, em vez de carregar o arquivo inteiro.
Se você precisa consultar apenas:
– tempo de permanência
– frequência
– data
– cluster comportamental
o motor analítico acessa somente essas colunas.
Isso reduz o tempo de leitura do arquivo, uso de memória e custo computacional.
Essa estrutura colunar permite três coisas fundamentais:
Primeiro, leitura seletiva: sistemas conseguem acessar apenas as colunas necessárias para uma análise específica.
Segundo, compressão mais eficiente: colunas com valores repetidos ou categóricos são comprimidas com muito mais eficiência do que dados organizados por linha.
Terceiro, performance analítica: operações como filtros, agregações e segmentações tornam-se muito mais rápidas em grandes volumes de dados.
Além disso, O formato parquet permite a gravação de mais de uma tabela de dados, e suas estruturas, o que simplifica o compartilhamento de estruturas complexas de dados
Ele não é apenas um “arquivo”. Ele é um formato projetado para processamento analítico em escala.
CSV é troca. Parquet é muito mais que isso. É processamento.
Formatos como CSV são excelentes para troca de dados. São simples, universais e fáceis de manipular.
O desafio aparece quando o volume cresce.
Quando falamos de:
– bilhões de sinais de latitude e longitude
– históricos temporais extensos
– múltiplos atributos por dispositivo
– cruzamento constante de bases
o formato começa a impactar a performance.
O .parquet foi criado justamente para ambientes de grande escala. Ele é um formato colunar, otimizado para leitura analítica.
Por que isso é relevante para mídia
Em operações que envolvem:
– GeoBehavior
– criação de audiências com filtros temporais
– atribuição de visitas físicas
– exportação para múltiplos canais
– consolidação de dados massivos de geolocalização
o volume de dados é estruturalmente grande.
Formatos otimizados como .parquet permitem que essas consultas sejam feitas de forma eficiente, viabilizando segmentações mais granulares sem comprometer performance.
Compressão e eficiência
Outro ponto importante é que o .parquet utiliza compressão e encoding por coluna.
Colunas com valores repetidos ou categóricos (como tipo de local ou cluster) ocupam menos espaço e são processadas com mais eficiência.
Isso impacta diretamente:
– armazenamento
– velocidade de leitura
– escalabilidade da infraestrutura
Conectando com a realidade da Hands
Quando falamos de MDM, Audience Hub, criação de audiências baseadas em comportamento real com exportação multicanal e reports de Store Visits estamos falando de arquiteturas que precisam lidar com alto volume e múltiplos critérios simultaneamente.
A escolha do formato de armazenamento é parte dessa estrutura.
Parquet não é apenas um detalhe técnico. É um dos elementos que permitem que dados massivos se tornem acionáveis.
Entender isso ajuda a enxergar mídia digital não apenas como ativação, mas como infraestrutura de dados.

Quando falamos em dados de geolocalização, muita gente imagina apenas um “pontinho no mapa”. Mas, na prática, o valor real desses dados está no padrão, não no ponto isolado.
Um único sinal de localização diz pouco. Agora, centenas ou milhares de sinais ao longo do tempo contam histórias.
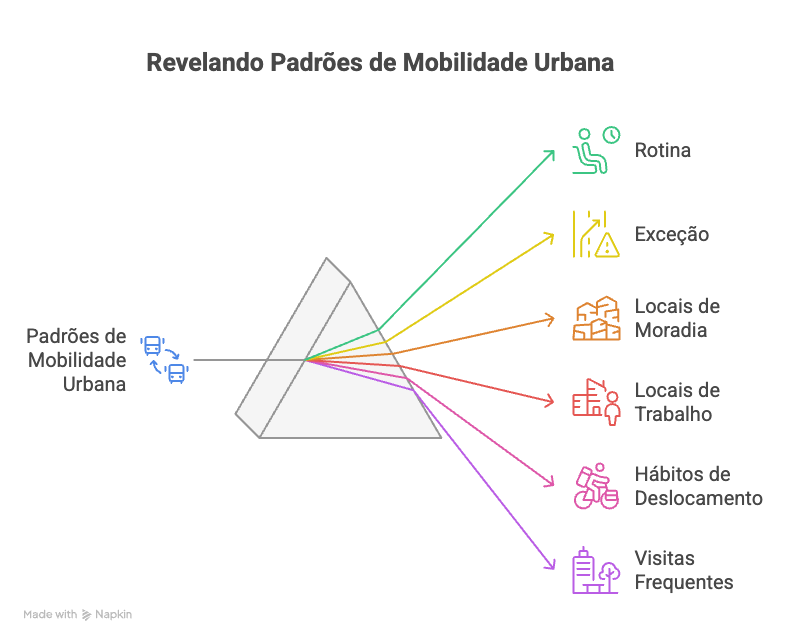
É a partir dessa repetição de horários, lugares e frequência que conseguimos inferir comportamentos, que aqui na Hands apelidamos de GeoBehavior lá em 2018. Através dele que desta análise que conseguimos inferir:
- Região provável de moradia
- Região provável de trabalha
- Lugares visitados com frequência
- Deslocamentos recorrentes que definem uma rotina
- Ou mesmo pontos ocasionais, mas que são relevantes por grande concentração de pessoas: shows, eventos esportivos, festas etc
Mas como organizar bilhões de dados de milhões de pessoas que podem estar em dezenas de milhões de locais? Simples, através de metodologias de estatística e probabilística, sem depender de dados declarados.
O desafio: transformar pontos soltos em comportamento
Os dados de geolocalização brutos costumam ter este formato:
- ID único do device
- Latitude
- Longitude
- Timestamp (data e hora)
Sozinhos, eles são apenas registros técnicos de localização cartográfica.
O desafio é agrupar esses pontos de forma inteligente para responder perguntas como:
- “Esse conjunto de pontos representa um local fixo?”
- “Esse local é visitado por outros devices? Na mesma data? Horário?”
- “Esse local é visitado com frequência suficiente para indicar rotina?”
- “Em quais horários esse local aparece?”
- “É um padrão recorrente ou algo pontual?”
É aí que entram as técnicas de clusterização espacial e temporal com uso de metodologia estatística e probabilística.
Uma das abordagens possíveis: DBSCAN
Existem várias formas de agrupar dados de geolocalização e uma delas, bastante conhecida, utilizada e eficiente, é o DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
Apesar do nome técnico, a ideia por trás dele é simples, o DBSCAN agrupa pontos que:
- Estão geograficamente próximos
- Aparecem com densidade suficiente
- Se repetem ao longo do tempo
E ele faz isso sem precisar que você diga antes quantos grupos existem e isso ajuda a identificar padrões e locais que não eram inicialmente conhecidos, ajudando a entender tendências antes mesmo que fiquem evidentes à olho nu.
Isso é especialmente importante quando falamos de comportamento humano, porque:
- As pessoas não têm um número fixo de lugares
- Algumas rotinas são claras, outras são mais difusas
- Sempre existem exceções, mas que podem ser relevantes (shows, eventos etc)
Como isso se aplica a moradia, trabalho e visitas?
Vamos trazer isso para um contexto prático.
1. Inferência de moradia
Em geral, um local de moradia apresenta padrões como:
- Alta recorrência
- Presença majoritária à noite
- Frequência durante finais de semana
- Permanência prolongada
Quando aplicamos uma técnica como o DBSCAN:
- Os pontos noturnos e recorrentes tendem a formar um cluster denso
- Pontos isolados (ruído) são descartados
- O cluster mais consistente nesse contexto pode ser inferido como provável local de moradia
Nada disso é uma “certeza absoluta” — é uma inferência estatística, baseada em padrão.
2. Inferência de trabalho
O raciocínio é parecido, mas o padrão muda:
- Presença recorrente em dias úteis
- Horários comerciais
- Menor frequência noturna
- Permanência concentrada durante o dia
O DBSCAN ajuda a identificar:
- Um cluster distinto do de moradia
- Com comportamento temporal diferente
- Com alta regularidade semanal
Isso permite inferir um provável local de trabalho, sem precisar que o usuário diga onde trabalha.
3. Lugares visitados e hábitos de consumo
Nem todo cluster é moradia ou trabalho e aí o DBSCAN pode ajudar ainda mais.
Alguns agrupamentos indicam:
- Academias
- Restaurantes
- Shoppings
- Hospitais
- Escolas
- Pontos de lazer
Aqui, o DBSCAN é útil porque:
- Identifica clusters mesmo com menor frequência
- Mantém pontos isolados como “ruído”
- Ajuda a separar rotina de evento pontual
Esses clusters alimentam análises como:
- Afinidade com categorias
- Hábitos de deslocamento
- Perfil comportamental urbano
Por que DBSCAN é uma das principais metodologias utilizadas para auxiliar a definição de GeoBehavior?
Em projetos com dados de geolocalização, o DBSCAN costuma ser interessante porque:
- Não exige número pré-definido de clusters
- Lida bem com ruído (dados esporádicos)
- Funciona bem em ambientes urbanos densos
- Se adapta melhor à imprevisibilidade do comportamento humano
Isso não significa que ele seja a única solução — mas sim uma alternativa robusta dentro de um conjunto maior de técnicas.
Na prática, projetos maduros costumam combinar:
- Regras de negócio
- Janelas temporais
- Clusterização espacial
- Validações estatísticas
- Camadas de privacidade e anonimização
Importante: inferência não é identificação
Um ponto essencial, e que vale reforçar:
Inferir comportamento não é identificar uma pessoa.
Essas análises trabalham com:
- Dados anonimizados
- Padrões agregados
- Probabilidades, não certezas individuais
O foco está em entender comportamento coletivo, gerar inteligência e apoiar decisões, sempre respeitando princípios de privacidade e conformidade regulatória.
Conclusão
Dados de geolocalização ganham valor quando deixam de ser pontos isolados e passam a revelar padrões de vida urbana.
Técnicas como o DBSCAN ajudam justamente nisso:
- Transformar volume em significado
- Separar rotina de exceção
- Apoiar inferências como moradia, trabalho e hábitos
No fim, o mais importante não é a técnica em si, mas como ela é usada, combinada e interpretada dentro de um contexto responsável e estratégico.
Se quiser saber mais sobre a metodologia DBSCAN ou como utilizar GeoBehavior no seu negócio, entre em contato com nosso time de especialistas.

O que é Hash?
No universo da tecnologia e da transformação digital, utilizar dados para otimizar os negócios é uma necessidade para qualquer tipo de empresa, mas a segurança da informação é uma das maiores preocupações ao avançar em busca de novas possibilidades.
Um dos grandes desafios é como transitar os dados entre áreas, plataformas e empresas, sem correr riscos com a exposição, ou mesmo vazamento, destas informações.
Para solucionar esse tipo de demanda existem diversos mecanismos e tecnologias como Tokenização, Criptografia, Anonimização etc, e uma das tecnologias mais conhecidas e utilizadas no mundo do marketing e mídia digital é o hash, que nada mais é que uma função matemática que transforma qualquer tipo de dado em uma impressão digital única, utilizada para verificar integridade, autenticar informações e proteger dados sensíveis.
Para que serve um hash?
O hash é amplamente utilizado em diferentes aplicações de tecnologia:
- Proteção de senhas
Em vez de salvar a senha real em um banco de dados, muitas aplicações armazenam apenas o hash. Assim, é possível fazer o “match” para validar o acesso de um usuário, mas essas informações não ficam disponíveis para ninguém, ou seja, mesmo que os dados sejam expostos, o invasor não tem acesso direto à senha original. - Blockchain e criptomoedas
O Bitcoin e outras criptomoedas usam o SHA-256 para validar transações e gerar novos blocos. Cada bloco contém um hash que liga ao anterior, garantindo a integridade de toda a cadeia. - Verificação de integridade
Arquivos distribuídos online muitas vezes vêm acompanhados de um hash. O usuário pode calcular o hash localmente e comparar com o fornecido para confirmar que o arquivo não foi corrompido ou adulterado. - Assinaturas digitais e certificados
Sistemas de autenticação e assinaturas eletrônicas utilizam funções de hash para garantir que os dados não foram alterados após a assinatura.
SHA-256
Dentro dos diversos tipos de hash, o que mais se popularizou no mundo do marketing digital é o SHA-256 (Secure Hash Algorithm 256 bits), que é uma função criptográfica que transforma qualquer tipo de dado — um texto, uma senha ou até um arquivo inteiro — em uma sequência única de 256 bits (ou 64 caracteres hexadecimais).
De forma “simplificada”, se é que podemos assim dizer, o algoritmo do SHA-256 pega o dado de entrada, processa em blocos de 512 bits e, por meio de operações matemáticas complexas, gera a saída em um bloco único de 256 bits.
Mas porque o SHA-256 é tão confiável e foi escolhido como padrão?
São três propriedades principais que tornam o Hash256 uma referência para diversas empresas e aplicações:
Unidirecionalidade
Diferente de outras criptografias, que através de uma “chave” podem ser traduzidas por terceiros, o Hash SHA-256 é praticamente impossível de ser revertido para se chegar à informação original. Isso porque, ele pega uma informação, “corta em pedacinhos” e faz um monte de contas para misturar esses pedaços até virar uma impressão digital única, impossível de desfazer. O SHA-256 usa apenas operações matemáticas básicas, mas repete isso tantas vezes que o resultado vira um código único e irreversível.”
Determinismo
Como a regra e padrão do algoritmo é sempre o mesmo, a mesma entrada de dado sempre resultará no mesmo hash, mesmo que seja criada em tempos diferentes, por pessoas diferentes, em qualquer lugar do mundo.
Por exemplo, se duas empresas possuírem um mailing com informações de emails e quiserem analisar quais destes e-mails existem em ambos os bancos de dados, sem precisar deixar evidente quais são os emails, ambas as empresas podem utilizar o SHA-256 para converter sua base de dados. Neste caso, como a regra é a mesma, caso um mesmo email exista nas duas empresas, o resultado da conversão será o mesmo, e com isso é possível fazer o match sem abrir o dado em si.
Justamente por esse tipo de aplicação do exemplo que ele é muito utilizado para match de dados e audiências, tema que vamos abordar mais adiante.
Sem duplicidade
Outro ponto importante é que a probabilidade de duas informações diferentes produzirem o mesmo hash é praticamente inexistente. O SHA-256 utiliza informações alfanuméricas e 64 caracteres. Se fizermos uma conta, que na verdade nem a maioria das calculadoras consegue fazer, o SHA-256 permite gerar cerca de 115 quattuorvigintilhão (não escrevemos errado não…) de possíveis resultados diferentes, e todos com o mesmo tamanho (64 caracteres hexadecimais). Para se ter uma idéia, o resultado da mesma ordem de grandeza do número de átomos do universo…
Mas porque o Hash256 é tão “famoso” na Mídia Digital
O sistema de hash SHA-256 acabou se tornando buzzword, e muito popular, no mundo da mídia digital pois é o sistema de criptografia padrão utilizado pelas principais plataformas de mídia digital para match de audiências First Party e Second Party.
A sua caraterística de determinismo, que explicamos acima, permite por exemplo que seja feita uma consulta para validar se uma base de emails First Party de um Anunciante existe ou não na base de usuários do Instagram, permitindo criar uma audiência específica com esses usuários, sem que o Anunciante e nem a Meta precisem exibir os dados reais de email de seus usuários.
Essa é também a forma como o Audience Hub da Hands atua para criar suas audiências exclusivas de geolocalização e GeoBehavior para ativação nos Canais Digitais. Após realizada a segmentação, a plataforma agrupa os IDs que representam a segmentação desejada e os transforma em hash SHA-256, permitindo então que seja feita a consulta e o match desta audiência em cada canal, sem que seja necessário abrir quais os IDs estão sendo utilizados.
Brincando de criptografia
Como exemplo simples podemos pegar como dado o email contato@hands.com.br.
Ao transformar essa informação em hash SHA-256, e o resultado será: 77fd45b668e795f580c8e09530d3b801531c907c542923725a3777cfa9c82fb9
Agora, se mudarmos um simples caracter, por exemplo indo de HandsUp para Hands_up, o resultado muda completamente: c0d4543338661e852ac149ca71f03b6c280f17d20fce0fa93db321d204afeeb2
Se para você o conceito ainda está um pouco subjetivo e não tão palpável, você pode até transformar isso numa brincadeira para entender na prática.
Partindo do básico, quem não se lembra da “Língua do P”? A brincadeira de criança que consistia em sempre incluir a letra P na frente de uma palavra. Bom, pense que isso pode ser considerado uma criptografia ou um hash, pois você está transformando dados seguindo um padrão.
Só que nesse caso existe uma “chave” pública, que é: “inserir P antes da palavra”.
Ou seja, qualquer pessoa que receber a mensagem, e “conhecer a chave”, sabe que basta tirar a letra P da frente de cada palavra.
Agora imagine que você criou um outro padrão, mais complexo, que ninguém sabe, como por exemplo alterar as letras de uma palavra avançando uma casa no alfabeto. Nesse caso, a palavra “Hands” viraria “Iboet”, ou seja, o H virou I, o A virou B, e assim consecutivamente.
Neste caso a “chave” para entender a palavra, que seria “avançar uma casa no alfabeto”, pode ser ou não ser pública, ou seja, você decidirá com quem compartilha. Porém, é possível entender qual foi a regra criada.
Quer fazer um teste?
Pegue o seu ChatGPT e utilize o prompt abaixo:
A palavra Iboet foi criptografada. Preciso de sua ajuda para (1) entender qual foi o padrão de criptografia e (2) descobrir a palavra original.
É muito provável que o GPT descubra rapidamente a regra, e te informe qual a palavra.
Já no caso do hash SHA-256 isso não acontece da mesma forma.
Vamos ao teste?
Volta lá no seu ChatGPT e utilize o prompt abaixo:
O dado 6b7204778686145fbdd0951b9815c72adce7e8e6bd67adfd299e23088622fe54
é de uma palavra que foi criptografada. Preciso de sua ajuda para (1) entender qual foi o padrão de criptografia e (2) descobrir a palavra original.
Muito provavelmente você vai receber do GPT um retorno informando que não foi possível identificar qual a palavra, isso porque nem mesmo o GPT consegue entender a regra por trás do SHA-256.
Mas agora, para fechar o entendimento, faça o inverso, peça para o seu GPT o seguinte comando:
Por favor transformar o dado Hands em hash padrão SHA-256
Você receberá como resultado uma sequência de números e letras exatamente igual a fornecida acima. Ou seja, o GPT não consegue retornar um dado que chegue à palavra original Hands, mas sabe a regra para transformar a palavra Hands em uma sequência exatamente igual a que criamos anteriormente.
-

 Geobehavior3 meses ago
Geobehavior3 meses agoAudience Hub: como funciona a tecnologia por trás da segmentação precisa da Hands
-

 Outros9 meses ago
Outros9 meses agoBem-vindo ao Hands Academy
-

 Outros9 meses ago
Outros9 meses agoConfira os detalhes do último Hands Quiz!
-

 Outros4 semanas ago
Outros4 semanas agoDBSCAN: a metodologia para o entendimento de comportamento baseado em geolocalização
-
 Geobehavior9 meses ago
Geobehavior9 meses agoOOH + Estratégias Mobile
-

 Geobehavior9 meses ago
Geobehavior9 meses agoGeolocalização + Plataformas Digitais (DSPs e Ad Managers)
-

 Geobehavior9 meses ago
Geobehavior9 meses agoGeoBehavior com foco em métricas e otimizações
-

 Outros6 meses ago
Outros6 meses agoHash: o que é, como funciona e porque quem trabalha com marketing digital precisa conhecer.